ScyllaDB LIVE - Essentials 29th Jan, 2025
Server configuration to run ScyllaDB on prem: Use a sizing calculator on ScyllaDB for AWS: I4i instance
https://www.scylladb.com/category/engineering/
Books: Database Performance at Scale (freely available online): https://www.scylladb.com/2023/10/02/introducing-database-performance-at-scale-a-free-open-source-book/
shard per code architecture: https://www.scylladb.com/2024/10/21/why-scylladbs-shard-per-core-architecture-matters/
ScyllaDB university: https://university.scylladb.com
Essentials track
Slides are available at scylladb university.
Basic Architecture
2 family groups: relational(SQL) and NoSQL databases
Below are outlines of NoSQL databases with increasing data complexity.
Key-value databases(redis, rocksDB) → Document databases(MongoDB, couchbase) → Wide column databases(ScyllaDB, Cassandra, DynamoDB)(database model using rows and columns) → Graph(JanusGraph, Neo4J)
ScyllaDB:
- Provides predictable performance at scale
- High availability
- High scalability (can add or remove nodes as the system is running)
- Performance
- Low maintenance
- Drop in replacement for Cassandra, dynamoDB
New feature: Tablet (Allows database to scale fast)
- Written in C++ , no need to worry about garbage collection like in Cassandra (written in Java)
ScyllaDB: All nodes are equal, no master or leaders. Uses Node Ring. Minimum nodes = 3 for a cluster
Keyspace: Contains tables, and has config such as replication factor, etc.
Each table needs to have a partition key. It can be one or many columns. Database will partition the data according to the partition key. It performs consistent hashing on those values.
Consistency Level(CL) Tuneable consistency. Can be per operation. It is = number of nodes that must ack a read/write. Example: CL = 1 | quorum | local quorum | ALL | etc
Higher consistency = lower availability (CAP theorem)
ScyllaDB supports LightWeight Transactions (LWTs) to atomically write with high consistency. Docs https://opensource.docs.scylladb.com/stable/features/lwt.html
Data modelling
In SQL, we think about data first, using entity diagrams, relationships. Then model them in the database, and at the end comes the application. We write queries at the very end.
Whereas in NoSQL, we think about data as well as application. We think about the possible queries, the consistency levels for queries before we model it.
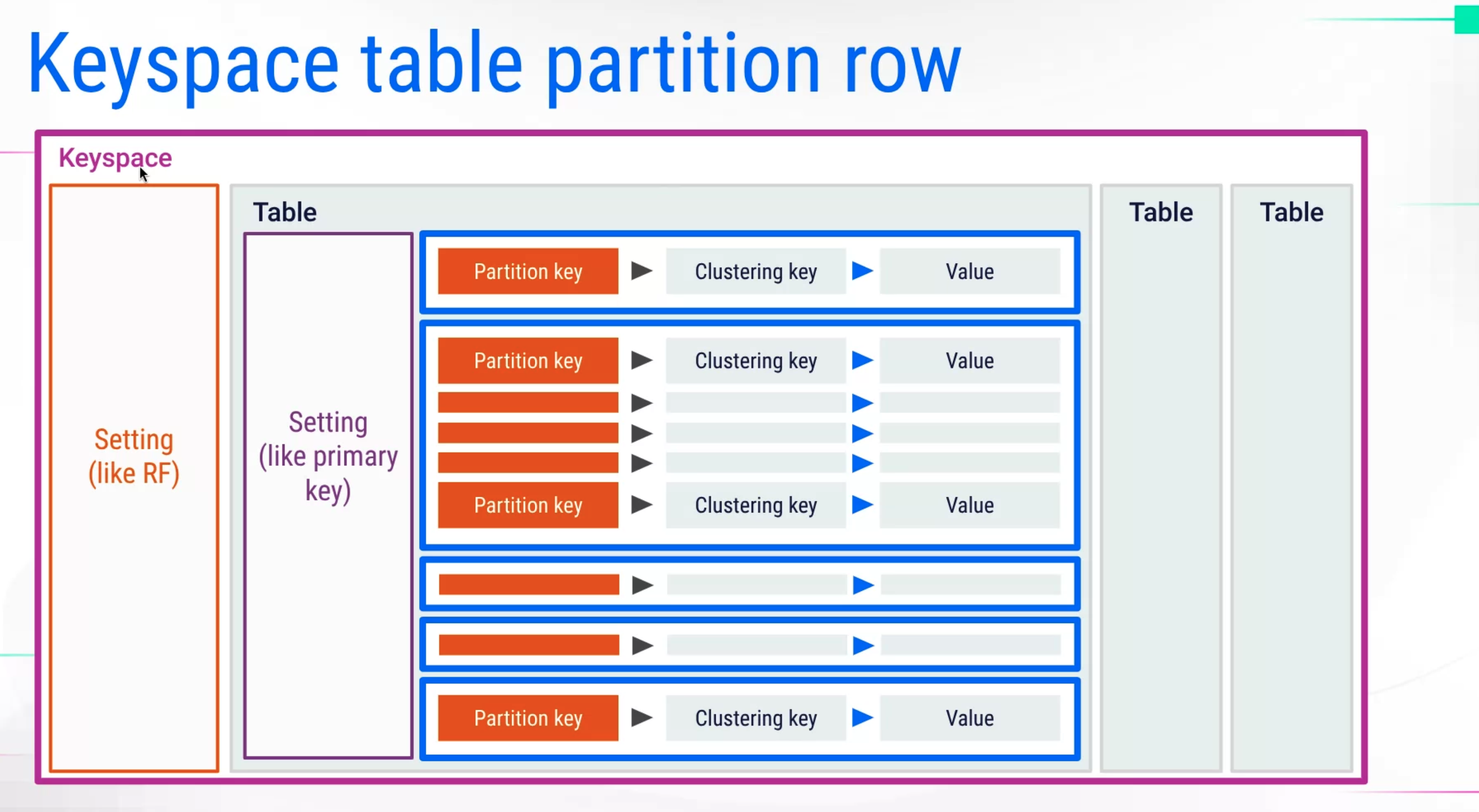
Data will be ordered according to partition key.
Clustering key can also be added. its similar to ordering key in dynamoDB (its optional).
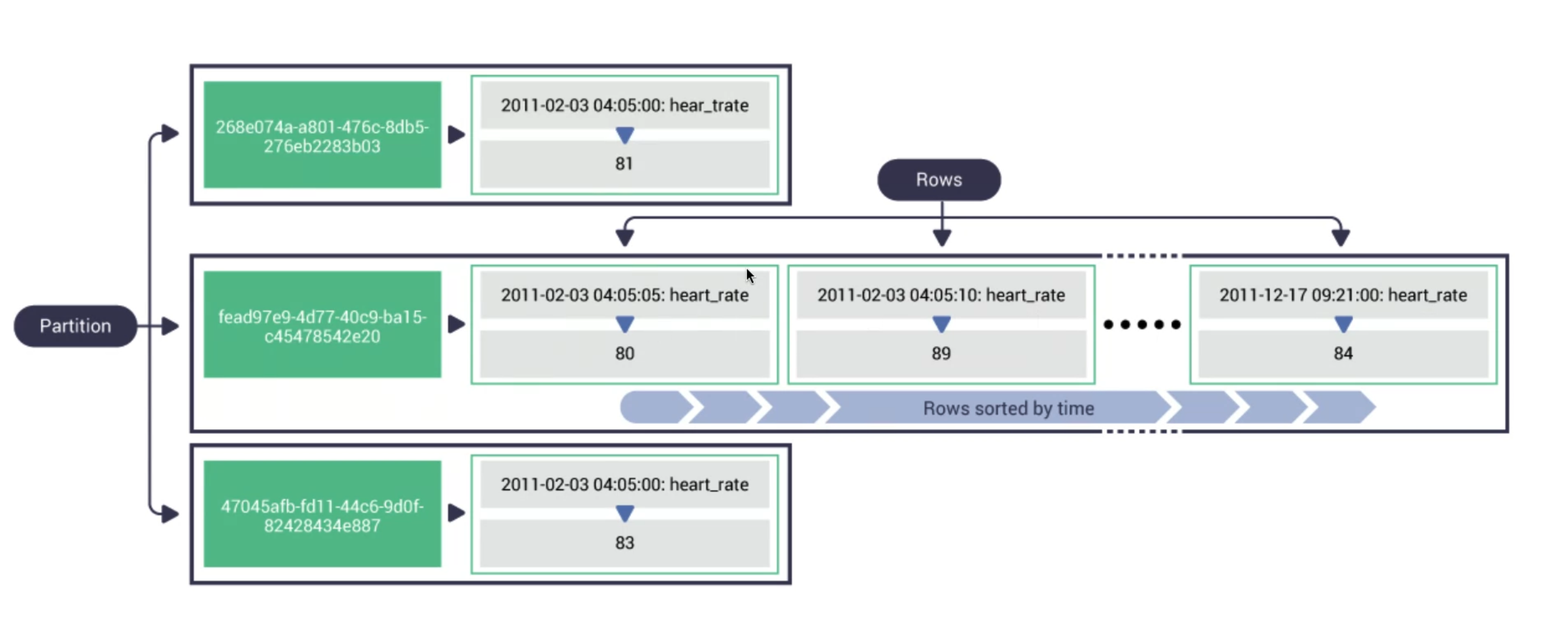
There can be multiple values for the partition key (in green). Data is sorted according to the clustering key.
Choosing a partition key
- high cardinality (means that, the column has lots of possible values). Example: application user reviews.
- even distribution
Avoid:
- low cardinality
- hot partition
- large partition
Any ID (user id) is a good candidate for a partition key. Use a monitoring tool always.
CQL also has collections as data types: sets, lists, maps
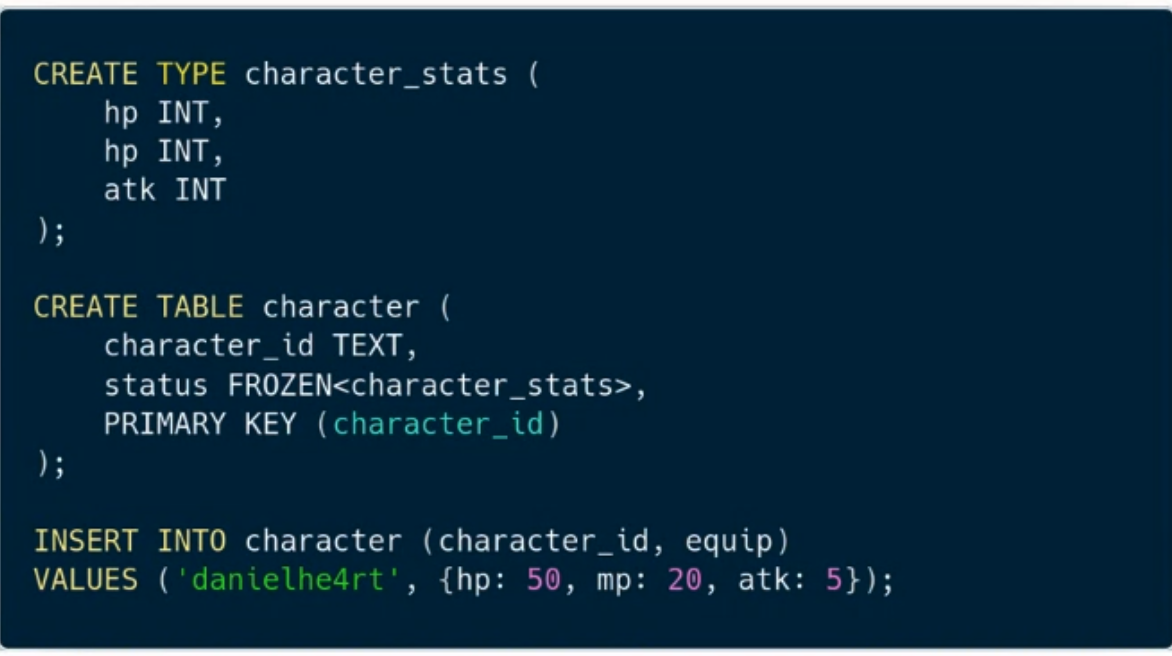
ScyllaDB also has UDT: User defined types (like a struct). Or a map with fixed keys.
ScyllaDB also has counters: Specialised data types designed for efficient inc or dec operations in a distributed database environment. You can not SET a value, only INC and DEC.
- Use prepared statements whenever possible. These types of queries are cached. Prepare the statement first and then fire the query with the dynamic values.
- Prefer token-aware policy: Basically, try to send the read request to the node which contains the partition. If this is not done, the node will randomly look for another node which contains the request partition which is an extra hop.
- How to write better apps (similar techniques as above): https://university.scylladb.com/courses/data-modeling/lessons/how-to-write-better-apps/
Materialised View: The same table replicated with different partition or clustering keys.