Postgres Full Page writes to WAL (Parameter tuning)
Checkpointing is a process where Postgres writes dirty pages from buffer pool to disk. This persists the change in data and marks a durable state.
Any changes to a page after checkpointing is risky as it is only modified in memory (buffer pool) and not on disk, we will have to wait for checkpointing to flush the dirty page to disk for it to be persistent.
To combat this, after the first change or update to a page after checkpointing, the entire copy of the page is written to WAL to persist the changes.
Postgres page size is 8Kb, and the entire 8Kb is written to the WAL even if the page contains data worth only 3KB. So 8Kb of space is occupied by the entire page that is modified.
Any further changes to the same page, will result only in a change log in the WAL and not the entire page again until another checkpoint occurs.
This is done incase the server crashes or loses power, the entire modified page is in WAL and can be recovered. Page size is 8Kb but linux OS page size is 4Kb, so essentially, during checkpointing, we are doing 2 writes to the OS 4Kb + 4Kb, and if one of the OS writes fail, we will end up with a torn page (half the page is corrupted). To mitigate this, the entire page is written to WAL which can be recovered.
Due to full page writes to the WAL, it might be slowing down writes. To improve performance, we can turn on WAL Compression, which would try to compress the 8kb page to smaller page depending on the amount of free space in that page. This works well for non random data. Random data leads to uneven compression which could not be beneficial. This can significantly improve performance on non random data tables (where data size per tuple is predictable).
Another optimization is to increase the checkpointing interval. Longer time between checkpoints means that subsequent updates to the same page will result only in change logs to the WAL and not full page writes. This might require increase in the WAL size max_wal_size.
There is a downside! Increasing checkpoint time and increasing WAL size will result in much longer recovery time. Basically, increase in downtime during crashes traded with higher throughput.
Always prioratize HOT updates
HOT updates significantly improve performance by not touching the index. To have HOT updates, we need to ensure we are not updating the indexed columns. Choosing indexes carefully can impact write performance.
Optimising BTree indexes
During high writes, if we have a sequential primary key, which is indexed, we will load essentially one btree leaf node, as it will be constantly updated as we bring in newer writes as its sequential, newer writes will sit in the same page. This will avoid FPW as the page will already be loaded.
Compared to random writes, incase we have a UUID index which is not sequential, random btree nodes have to be loaded leading to more FPWs. Basically ensuring that you are not touching a lot of btree nodes, so lesser FPW.
An interesting idea is to prefix UUID by date/timestamp to make it right leaning. This leads to less btree node accessed.
Vacuuming for performance
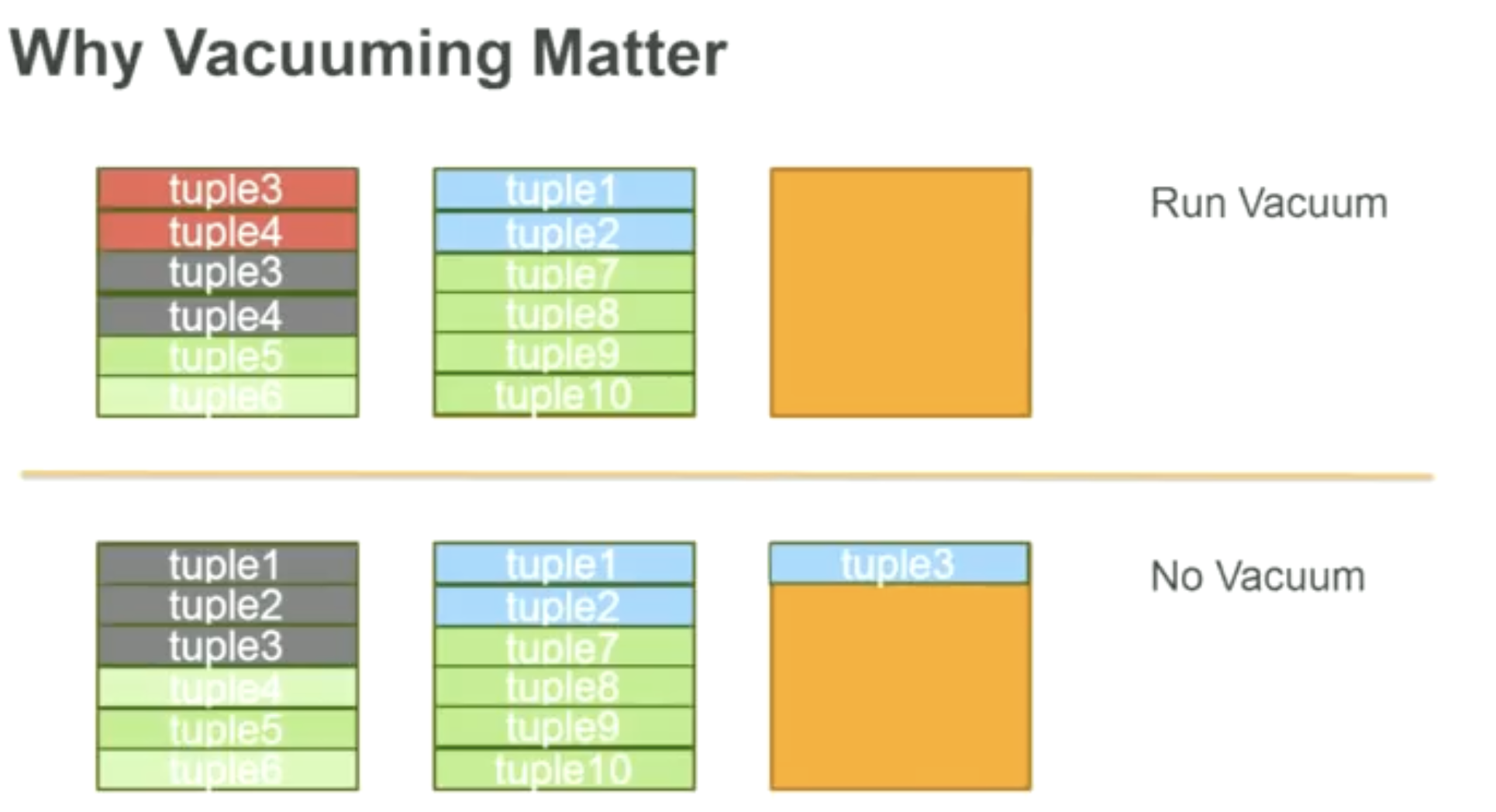
without vacuuming, leads to more pages to be created as old pages cannot be reused. more blocks = more cache misses, non HOT updates & more FPW
If we vacuum, we clean up dead tuples, creating space for newer tuples in the same page, where might lead to less cache misses and less FPW.
Vacuuming in memory
Can save time in insert heavy workload for freezing.
Aurora Postgres
Better optimised, how? TODO